人工智能驅動信息技術體系重構與再造——兼評《中國至2050年信息科技發展路線圖》
中國網/中國發展門戶網訊 2009年,以李國杰院士為組長的中國科學院信息科技路線圖專家組,出版了《中國至2050年信息科技發展路線圖》(以下簡稱《路線圖》),并于2013年出版的《科技發展新態勢與面向2020的戰略選擇》中發表《信息科技:加速人—機—物三元融合》(以下簡稱《三元融合》)。《路線圖》和《三元融合》前瞻性、戰略性分析了我國信息科技未來幾十年發展的大趨勢和戰略重點,為當時我國信息科技發展方向和戰略重點圈定了相關重點領域,對我國信息科技領域的重大科研活動起到了一定的指引作用。近15年來,全球信息科技發展已經發生了一系列重大的變化,尤其是近幾年來,以大模型為代表的新一代人工智能技術極速發展,為信息技術體系重構與再造創新帶來了重大的機遇,將加速驅動信息技術體系創新進程。因此,評估十幾年前出版的《路線圖》和《三元融合》中對信息科技相關戰略預判的一些結論與影響,并在新形勢下,進一步前瞻未來10年信息科技變化趨勢,為搶占信息領域科技制高點,到2035年實現科技強國等戰略目標,具有重要的現實意義。
《路線圖》和《三元融合》的重要預判與近15年發展的比較
回顧近15年來,信息科技發展變化與《路線圖》和《三元融合》給出的預判,現在看來,很多當初的預判至今依然適用。
關于信息科學理論發展的長期預判符合預期
《路線圖》認為:信息技術不會變成以增量改進為主的傳統產業技術,而是面臨一次新的信息科學革命。信息技術的基礎理論大部分是在20世紀60年代以前完成的,近40年信息科學沒有取得重大突破。上一次基本創新(即基于科學突破的重大發明)的高峰期是在20世紀40年代,現在已有大量的知識積累,按照經濟與技術發展長波規律的推測,21世紀20—30年代可能出現基本創新的高峰。2020年以后什么技術將成為新的主流技術就會逐步明朗;2020—2035年將是信息技術改天換地的大變革期。預計21世紀上半葉將興起一場以高性能計算和仿真、網絡科學、智能科學、計算思維為特征的信息科學革命。在網絡科學和智能科學取得重大突破以后,21世紀下半葉,基于信息科學的新的信息技術將取得比20世紀下半葉更大的發展。
近幾年,人工智能(AI)突飛猛進,驗證了《路線圖》的基本預判。AI現有重大技術發明,如Transformer深度學習框架,是基于Geoffrey Hinton等科學家長期對神經網絡模型的基礎理論研究成果。深度學習的黑盒模型為AI科學研究提出了急需解決的科學問題,需求的牽引必將引發科學的突破。當前AI技術的大發展,預示人類已經處在進入智能時代的前夜,目前的技術離實現真正的通用人工智能(AGI)還有一定的距離,再經過10—20年的努力,大概率有基于重大科學突破的基礎發明,如同20世紀40—60年代一樣,發明計算機和集成電路以后,人類就進入了信息時代。
關于信息技術發展的長期預判基本符合預期
人—機—物“三元融合”預判正在成為現實
《路線圖》和《三元融合》指出,人—機—物三元融合強調的是物理空間、信息空間和社會空間的有機融合,物理空間分別與信息空間、社會空間源源不斷地進行信息交互,而信息空間與社會空間則進行著認知屬性和計算屬性的智能融合。
近15年來,人—機—物三元融合正在加速。快速發展的移動互聯網、物聯網、4G/5G高速接入網及邊緣智能等,為實現人—機—物三元融合準備好了物質條件,數據智能化為智能融合提供了紐帶,計算機系統的基本模式正在從人機共生向人—機—物三元融合世界發展。移動互聯網實現了人與人的互聯、融合,物聯網(傳感網)實現了人與環境的互聯與融合,工業互聯網實現通過網絡連接各種工業設備和系統,實現工業數據的實時傳輸、共享與智能化處理,并通過新一代智能模型,改善、提升工業生產效率和質量,以及成本控制等。人—機—物三元融合最顯著的是腦機融合,腦機神經連接是重要的科技突破。埃隆·馬斯克的“神經連接”公司,繼首例人腦設備植入手術順利完成后,2024年7月迎來第2名人類植入者。通過在人腦皮層植入Neurolink相關芯片并采用大約10 bits/s的通信速率,使得癱瘓病人能夠通過思考來控制他們的手機或電腦。這真正實現了人—機—物三元融合。Neurolink成為現實,也預示著《路線圖》指出的,“今后幾十年內模擬計算可能又會成為受人重視的研究方向。我們在重視數字技術的同時,還要探索模擬量處理的新途徑以及數模混合處理的新方法”,這一預判得到一定程度的驗證。
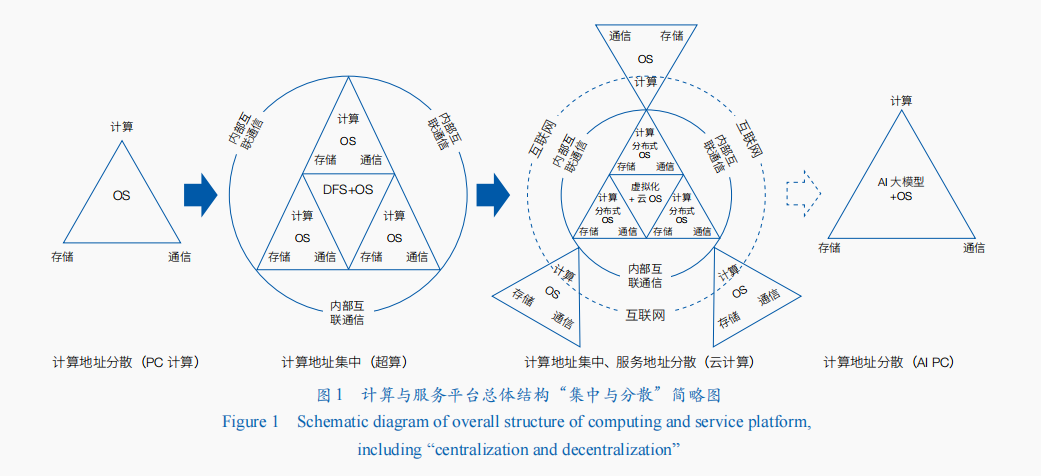
計算與服務平臺的總體結構依然呈現出“集中與分散交替為主舞蹈場地”的發展規律
《路線圖》指出,計算與服務平臺的總體結構幾乎是每隔20年左右有一個重大的變革,呈現出計算資源集中與分散交替為主的“三國定律”。目前,在“AI大模型+Agent”“AI大模型+RAG”等模式的加持下,未來這種集中與分散交替為主的發展規律將繼續延續。裝載有輕量化AI模型+Agent或+RAG或+Copilot的AI PC,將進一步改變人們使用計算機和互聯網的模式。一方面,計算與服務模式分散化的AI PC將進一步解耦人們對集中化的計算資源的需求,以及緊耦合的服務模式;另一方面,集成式的多云系統、聯邦云系統、超算互聯網等,將進一步提升計算資源的最大化利用(圖1)。因此,《路線圖》所指出的計算與服務平臺的集中—分散交替的“三國定律”,在未來還會繼續演進。這種周期性的變化,使得信息技術領域始終保持著創新的活力。
集成電路領域延續創新變革發展態勢
《路線圖》指出,集成電路領域將延續摩爾定律(more Mooer)、擴展摩爾定律(more than More)和超越CMOS(beyond CMOS)3個路徑發展。
在延續摩爾定律方面,晶圓級的大芯片已經成為芯片結構橫向擴展發展的重要成果。2012年后登拉德縮放比定律受限,摩爾定律發展速度雖然放緩,但圍繞縮小COMS工藝特征尺寸、提高集成度,以及通過新材料的應用和器件結構的創新來改善電路性能的努力仍然在繼續,FinFET結構和工藝技術在半導體制程發展到22—5 nm過程中,發揮了重要的作用。2020年,在同行都在將晶圓分割成數百顆獨立芯片之時,美國Cerebras Systems公司則是選擇將整個晶圓做成一顆芯片,其發布的WSE-2二代晶圓級芯片,采用CMOS 7 nm工藝制程,集成了1.2萬億個晶體管、40萬個核心。這也是FinFET結構和工藝發展的重要成果之一。近年來,我國由于在集成電路領域受到“卡脖子”,與FinFET同時代發明的FD-SOI技術也被重新撿起來,成為破解之道之一。
在擴展摩爾定律方面,近些年來,基于先進封裝技術的Chiplet發展起來。Chiplet技術允許將整個芯片拆分成多個較小的、可以用不同工藝制造的不同模塊,然后通過高速互連方式集成到一個封裝中,實現全功能的芯片系統,從而優化性能、功耗和成本。因此,Chiplet技術被視為一種可以拓展摩爾定律的方式,延續了集成電路行業提高性能和降低成本的趨勢。咨詢機構Markets.us研究報告稱,在2023年,CPU Chiplet占據了主導市場地位,CPU Chiplet市場份額超過41%。雖然GPU Chiplet市場份額低于CPU Chiplet,但在專業應用領域發揮了關鍵作用。此外,通過傳統微電子工藝,實現光電子器件和微電子器件的單片集成的硅基光電子集成技術,有效解決了集成電路芯片目前金屬互聯的帶寬、功耗和延時等問題,也實現了擴展摩爾定律。
在超越CMOS方面,碳納米管晶體管已經展現出超越商用硅基晶體管的性能和功耗潛力,碳基集成電路技術成為重要發展對象。2019年8月,美國麻省理工學院的Gage Hills等在Nature發表論文,報告了碳納米管芯片制造領域的一項重大進展:一個利用14702個碳納米管晶體管構成的16位RISC-V指令集微處理器RV16X-NANO,該處理器采用兼容CMOS工藝制造,證明可以完全由CNFET打造超越硅的微處理器,為先進微電子裝置中的硅帶來一種高效能的替代品。2024年7月,北京大學基于碳納米管晶體管新型器件技術,結合高效的脈動陣列架構設計,成功制備了世界首個碳納米管基的張量處理器芯片,可實現高能效的卷積神經網絡運算。
此外,近15年來,集成電路芯片發展的“牧本周期”還在延續,能夠實現更好性價比的領域專用架構(DSA)處理器,如NPU、TPU、DPU等各種“XPU”,應運而生。國內研發的深度學習系列處理器寒武紀、類腦天機芯、天眸芯和市場上自動駕駛芯片等屬于 DSA 范疇。同時,核心數增多的通用架構的多核和眾核處理器仍然在發展,如X86系列CPU處理器和NVIDIA的系列GPU處理器。
軟件工程的摩爾定律日益顯現
《路線圖》指出,軟件工程的發展走勢將類似于摩爾定律,今后幾十年內如果能夠使得軟件業和服務業也產生摩爾定律現象,無疑將會引發一場革命。目前,基于LLM大模型的AI編碼生成助手,為軟件工程的摩爾定律提供了依據。如谷歌首席執行官曾透露,該公司通過在代碼自增長工具中集成大模型,生成了這家科技公司超過1/4的新代碼,包括自動導入包、自動生成構造函數等。目前AI輔助編碼方面,出現了兩大發展方向: AI編碼助手或者AI代碼生成器大量涌現,如美國GitHub與Open AI合作推出的GitHub Copilot、亞馬遜的CodeWhispere等;傳統的低代碼/無代碼工具,大量引入AI輔助功能,如低代碼開發旗艦公司OutSystems通過Mentor新型生成式AI驅動的“數字工作者”改變了整個軟件開發生命周期。統計顯示,目前軟件工程師基于大模型開發應用軟件,時間上可以節約20%—30%。隨著面向軟件開發的專用大模型能力日益增強,在軟件工程領域的摩爾定律也將有望成為現實。
未來10年信息技術體系重構與再造的創新機遇與挑戰
《路線圖》預測,2020—2035年將是信息技術改天換地的大變革期,將可能出現基本創新的高峰。自2019年以來,AI大模型的大發展表明,信息科技已經進入到基本創新突破期的前夜。在全球信息技術創新進入緩慢期的背景下,AI將加速信息技術體系的創新進程。因此,未來10年將是信息技術體系重構與再造的創新機遇期。一方面,對于原理還不太清楚的AI科學,一定還會有大的突破;另一方面,信息領域的科學與技術融合發展將成為大趨勢,并且信息技術將成為信息科學發展的主要推動力。更重要的是,新一代AI將加速驅動計算技術體系、數據空間技術體系、網絡空間技術體系和智能空間技術體系的重構與再造。
信息技術體系重構與再造創新的歷史演進
人類對信息技術體系重構與再造創新一直沒有停滯。
在處理器方面,從4位微處理器到64位處理器,從復雜指令集(CISC)到精簡指令集(RISC),從一級緩存到二級、三級,執行從順序指令執行到亂序指令執行,從單一核心架構到多核心架構、眾核心架構,從通用功能架構到功能專用架構并存,從單個芯片到異構集成封裝多核心、多功能的芯片等。目前,在AI等領域對算力提出更大需求的牽引下,晶圓級大芯片也被開發出來。
在計算機體系結構方面,20世紀50—60年代,為實現資源的最大化利用,通過分時操作系統提高指令執行效率的批處理計算機得到快速發展。此后,為提高指令并行性進一步提高計算機運行速度,指令流水線技術取得重大突破;為了進一步突破計算性能瓶頸,超標量與超長指令字兩種計算機體系結構應運而生。再后來,多任務、多個處理器并行執行的并行計算體系在一系列超級計算機中得以廣泛應用。近年來,面向大數據、云計算和AI等發展需求,按照數據流動規律進行組織和管理的數據流體系結構重新得到重視,成為計算機體系結構發展的“老樹新芽”技術。
在信息技術產品生產方面,從早期的由一家廠商包攬了一個計算機的軟件、硬件設計與制造的垂直體系,向多廠商分散、配合生產各自優勢產品的扁平化體系方向發展。例如,早期的美國IBM公司生產的大型計算機,其操作系統、CPU、存儲器等都是由IBM自己設計、生產和制造。隨著微軟Windows操作系統、Intel CPU等的成熟商用,計算機生產商不再做垂直化產品研發的工作,而是將其他廠商小樹屋的產品進行扁平化分工、整合,由此形成了“Windows+Intel”(Wintel)計算產品體系,并形成了牢固的產品迭代節奏,至今形成了“Wintel”、“ARM+Andrio”和“ARM+iOS”體系。目前,由于GPU和Transformer架構在AI大模型領域的成功,“NVIDIA+Transformer”體系已經基本形成。
計算技術體系重構與再造
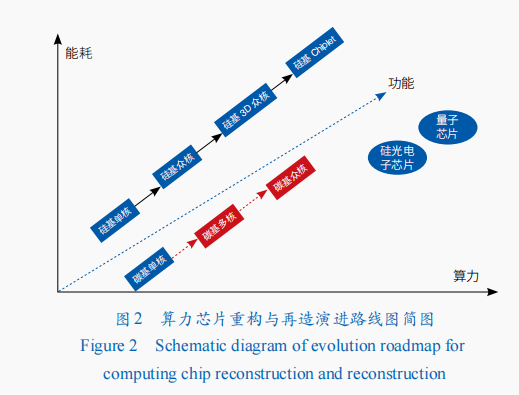
近年來,全球信息技術重大創新的整體節奏在放緩。未來10年,在人工智能發展驅動下,計算技術體系創新將快速推進。一方面,進入后摩爾時代,為追求算力增長和功能豐富,計算處理器芯片將繼續向低成本、高良率的Chiplet堆疊集成芯片和3D芯片方向發展,異構集成創新成為產業技術主要發展方向,晶圓級大芯片將成為重點發展方向之一;同時,功能豐富的低世代工藝智能芯片、新型硅光電子芯片、碳基芯片,以及非馮·諾依曼體系結構量子計算芯片,也將快速向前發展(圖2);另一方面,算力空間將向算力聚合與服務能力提升方向前進,將由超級計算、云計算,向云聯邦、超算智算融合、算網融合等方向發展(圖3)。

處理器技術體系重構與再造
在處理器設計環節,芯片設計的復雜性日益呈指數級增長,導致設計周期長、成本高,傳統的設計方法難以應對這種復雜性。未來10年,AI技術將成為優化處理器芯片設計過程的關鍵工具,提高設計效率和質量,并生產出性能更高的芯片。2024年3月,美國白宮科技政策辦公室發布《國家微電子研究戰略》,明確提出加強將AI和機器學習及基于物理的方法集成到EDA工具中。在2024年全球芯片領域頂會Hotchips年會上,多個報告展示了AI輔助芯片設計的重要成果。其中,美國Synopsys公司報告了強化學習(reinforcement learning)在芯片設計中的應用,其Synopsys.ai套件,在大語言模型支持下,在整個EDA堆棧中充分利用生成式人工智能(AIGC),用于RTL(register-transfer level)設計、驗證及其他輔助資料創建的生成功能等。在處理器制造環節,比利時微電子研究中心(IMEC)發布的工藝路線圖指出,FinFET晶體管結構將在3 nm走到盡頭,然后過渡到新的GAA(gate all around)結構,集成電路工藝尺度將進入埃米階段。此路線圖提出的CMOS 2.0范式愿景指出,CMOS 2.0是通往真正3D芯片的道路。但這種方法面臨的挑戰在于將嚴重依賴后端供電網絡(BPDN),會將所有供電改到晶體管的背面,并需通過系統技術協同優化(STCO),重新思考設計過程,改變設計方法。相對于硅基集成電路計算芯片,碳基芯片具有良好的低功耗、與硅基工藝兼容良好等特點。如前文所述,目前碳基芯片已經取得積極進展,將成為未來與硅基芯片并行發展的主要方向之一。
從更長期來看,處理器芯片重構與再造創新發展趨勢體現在如下5個方面:電路理論方面,從電子電荷向分子、極化、強電子相關態、自旋方向等方向發展;材料方面,從硅基向碳基、宏觀分子材料、納米結構、復合金屬氧化物等方向發展;器件結構方面,從CMOS器件向分子器件、自旋器件、鐵磁性器件、量子器件等方向發展;數據載體方面,從模擬量、數字量向量子位等方向發展;系統結構方面,由馮·諾依曼架構、多核眾核架構,向可重構、量子、神經形態學計算架構等方向發展。目前,量子計算還處在探索階段,主流方案包含超導、離子阱、光量子、超冷原子、硅基量子點和拓撲等多條技術路線,基本都沿著量子計算優越性由專用量子計算向通用量子計算的路線圖發展。
對我國而言,在FinFET時代,集成電路制造正在面臨美國聯合其盟友的打壓、封鎖,向更先進制程工藝芯片制個人空間造發展受阻,同時X86、ARM指令架構也存在需要授權的制約。隨著集成電路制造工藝向3D方向發展,前道工藝光刻機的作用將會減弱,刻蝕機、薄膜機和電子束檢測設備等作用將會增加,我國發展集成電路技術與產業有了新機遇。因此,我國一方面要積極發展集成電路先進制程制造工藝技術,研發先進制程的前道工藝極紫外光刻(EUV)設備;另一方面,要積極推動發展刻蝕機、薄膜機、電子束檢測設備等,向滿足3D芯片制造工時租會議藝方向發展。此外,基于先進封裝的Chiplet技術,以及與FinFET同時代產生的FD-SOI技術,也可能為我國計算芯片發展提供新的選擇。FD-SOI是不同于FinFET的技術與工藝路線,是一種平面工藝技術,具有減少硅幾何尺寸同時簡化制造工藝的優點,在22/12/10納米FD-SOI技術性能與14/7/5納米FinFET技術相當;并且,FD-SOI相比FinFET,具有PPA平衡性好等特點。但目前主要集成電路制造設備與工藝是圍繞FinFET生態的;FD-SOI面臨的挑戰是還沒有建立完整的產業鏈生態,擴大市場難。
算力空間技術體系重構與再造
為適應人工智能等領域對更大算力和多種資源協同服務的需求,未來10年,面向應用的計算將與智能計算深度融合,表現為臨近互聯、封裝集成、大規模向量化等,并期待RISC-V+AI Core指令接口的標準化。在AI發展驅動下,算力空間重構與再造的一個重要方向是優化馮·諾依曼架構,即在一個計算機系統內部區域做工作,想辦法通過減少內存和處理單家教場地元之間的路徑,實現高內存帶寬及較低的訪問開銷,打破馮·諾依曼架構“存儲墻”和“功耗墻”等問題,實現更高效能的計算。
在AI計算方面,由于不同模型對算力和帶寬的需求不同,如基于Transformer的LLM計算中,性能瓶頸常常是在帶寬而非計算,即帶寬跑滿、算力閑置。為此,存算一體、存內計算(PIM/PNM)技術路線被提出,利用片內的高帶寬,處理常見的矩陣運算和部分向量運算。具體是通過TensorCore(張量計算核心)的乘累加單元陣列提供算力,通過HBM的高帶寬使數據能源源不斷到達TensorCore。在AI計算中,雖然PIM/PNM可以減少數據從內存讀取的時間,提高計算效率,從而加速模型的訓練和推理過程,但其面臨眾多技術挑戰,包括將計算單元集成到內存芯片中的復雜性、功耗和散熱問題,以及數據一致性和可靠性問題等。
在片上和集群的算力互聯方面,使用片上光網1對1教學絡(ONoC)連接多個同構的處理單元,如互聯CPU、AI Core等,這是將光集成電路(PIC)作為NoC與AI Core的硅片集成,封裝成一個AI芯片,直接在芯片上做光電轉換輸出到光纜,實現了芯片之間的互聯。基于光網絡的互聯方案與動態調度方面,如Google TPU4 AI訓練集群的光互聯方案,是將64顆TPUv4以4×4×4的方式構成一個三維立體結構Cube,并且這個AI訓練集群的拓撲互聯方案的重構,可根據需求實時對AI計算資源縮容和擴容。
面向人—機—物三元融合的廣泛應用場景,AI等算力與服務需求以及高性能計算機(超算)從E級向Z級發展面臨諸多難題,未來將跨網域、多異構的算力與服務聚合是一條重要的發展途徑。將超算、智算和量子計算等多種異構算力資源融合,并結合算力網實現算網融合是一個大膽的創意,但多種異構算力資源的融合是一個難題。例如,AI算力主要由基于GPU、NPU等芯片,但AI的應用通常會同時用到CPU、GPU、TPU等,怎么解決CPU運算與GPU、TPU等運算銜接是個難題。因此,需要解決多種算力資源虛擬化、接口標準統一、高效協同計算、應用任務分布與調度、編程模型等難題。同時,異構算力如何與算力網進行融合也是個難題,需要突破原有的并行計算、云計算等思想,進行顛覆性的創新。為此,需要進行原理性創新和技術實驗的重大科技基礎設施來支撐。自2023年以來,美國IBM、微軟、英偉達、谷歌等公司分別合作,在構建量子—超算異構融合算力平臺方面取得進展,如IBM利用127比特量子云平臺與“富岳”超算的結合,實現了包含28個原子的FeS團簇分子計算。這為多種算力融合技術發展路徑提供了很好的借鑒。
數據空間技術體系重構與再造
數據已經成為AI大模型發展的三大核心要素之一。中國工程院發布的《數據空間發展戰略藍皮書(2024)》(以下簡稱《藍皮書》)定義的未來數據空間是:人—機—物互聯,產生大量數據,通過社會再生產,數據又作用于人—機—物,這一實踐活動最終形成了人類活動的新空間。即:在AI發展驅動下,共享空間數據空間將由單一計算機系統的數據空間、基于互聯網的數據中心空間,發展到人—機—物融合的人類智能活動空間。因此,未來10年,構建面向人類智能活動的數據空間技術體系,是一項重要任務。
在AI發展需求驅動下,構建面向人—機—物三元融合的人類智能活動的數據空間,還面臨眾多挑戰,主要包括:理論范式問題。基于什么理論來支撐數據空間構建,是基于自組織理論還是他組織理論?基于自組織理論要研究數據空間構建是怎樣從混沌無序的狀態向穩定有序的終態的演化,以及系統內部各要素之間的協同機制。基于他組織理論,要研究數據空間構建需要設計怎樣的制度、政策及機制等外部力量,推動數據空間的建立。此外,對于數據空間建立的復雜度,是基于機械論還是耗散結構理論(即是強調將數據空間系統是由數據孤島構成,通過系統組織形成“整裝數據”結構),還是強調引入負熵來形成有序數據空間結構?等等。技術問題。數據空間的架構是什么?各個數據孤島是通過什么方式進行連接?聯接協議是什么?接口是什么?有什么標準?如何保護各個數據源的數據隱私與安全?數據空間中的數據如何進行統一標識?如何封裝?數據空間如何與算力空間進行耦合?數據空間的各類數據如何統一標識和表示,以便于進行綜合挖掘和智能應用?等。目前,《藍皮書》為此提供了一些參考,包括把數據空間看作一個數據要素場、構建數聯網根服務體系,以數聯網、數據標識、數據向量化、深度神經網絡學習及AI大模型等為技術應用體系等。
網絡空間技術體系重構與再造
幾十年來互聯網體系結構保持相對穩定,但依然存在兩大問題:魯棒性差,脆弱,不安全;適應性弱。為此,國內外對互聯網體系結構的創新努力一直在持續,基本上采取漸進式和變革性兩條技術路線,即:采用“自下而上”打補丁的方法,升級更新具體技術適應新業務和新終端;采用“自上而下”完善體系結構,從根本性解決問題和克服挑戰。變革性的技術路線是采用“推倒重來”的思路設計全新網絡,國內外先后開展了New Arch、Clean Slate、GENI、FIND、FIA、FIRE、新一代互聯網體系結構理論、面向服務的未來互聯網體系結構與機制等研究計劃或項目,先后提出了Open Flow、SDN、NDN、CCN等互聯網體系結構的新設想和新技術。
未來10年,AI將驅動網絡空間技術體系從硬件鏈路到網絡協議,乃至網絡應用的全體系的創新。除了在新型網絡架構、尋址路由、內生安全等領域繼續突破創新外,互聯網體系結構還將向智能化、敏捷化、網存算一體化不斷發展,從而支撐超大規模、人—機—物融合、跨時空壁壘的智能連接與服務。隨著AI技術的發展,互聯網將圍繞4個方面進行創新:網絡設備方面,將AI能力下沉到網絡設備。通過感知業務質量,感知信道性能等,讓網絡設備具有更強的感知能力,以便更好地優化網絡,提升網絡為特定業務的服務能力。路由協議方面,通過增強數據面網絡層的能力,簡化控制面和管理面,滿足應用需求的多樣性,并提升邊緣能力來降低對中間節點的要求。通過協議的簡化和優化,使得網絡可感知、可溯源、可定位,實現更好的性能及內生安全要求。網絡管理方面,首先是網絡本身的智能化,隨著AI大模型在網絡管理中的應用,提升網絡智能化水平,讓網絡能夠具有自動駕駛、自動發現、自動配置、自動維護的能力;其次,網絡需要能夠適應更多業務發展,具有更好的開放性和安全性,為云網融合、算網融合實現資源一體化調度。安全方面,改變過去網絡安全被動式響應和防御的方式,未來要從網絡設備的內生安全,到端到端的云、網、邊、端協同防護體系的構建,持續提升網絡安全防護能力。
智能空間技術體系重構與再造
人類大腦是一個既能處理專用任務又能處理通用任務,并具有“自覺意識”的低能耗智能空間。信息領域的智能空間是人工智能融合的空間,是能處理各種模態信息的智能體的集合,其愿景是構建像人類大腦的智能體,使得處理各種專用任務的智能與處理通用任務的智能進行深度融合,解決智能碎片化的問題。
2024年諾貝爾物理學獎和化學獎都頒發給機器學習領域的科學家,表明以機器深度學習為代表的AI,成為未來10年最有前景的技術。近年來,以大模型為代表的新一代人工智能的研究和應用取得突破性進展,催生AI新的理論和應用范式,推動AI理論和應用進入新的發展階段。美國Open AI公司的ChatGPT成為新一代人工智能發展的分水嶺。AI大語言模型技術不斷成熟,率先在文本AIGC產生大規模應用,并催生圖像生成模型蓬勃發展,如DALL-E2、Stable Diffusion等。大模型從“一專多能”向“多專多能”前進,帶動新一輪應用范式創新。AI大模型技術也使信息領域的科技創新和產業生態發生巨變,促進了從底層芯片到應用的穿透式的技術與產業生態重構,并將逐漸重構數據空間、算力空間、開發框架、算子庫,乃至基礎芯片、系統及開源和應用服務模式等。AI for science正在重構科學研究范式(AI4R),加速驅動科學研究進程,產生顛覆式突破。當前,AI for science已經在生物領域取得顯著成效。例如,2024年5九宮格月,美國Google旗下DeepMind公司發布的新一代AI模型AlphaFold3,能夠預測蛋白質、DNA、RNA、小分子等的幾乎所有生物分子結構和相互作用;AI for Scinence已經在內嵌物理模型的神經網絡(PINNs)、約束條件下組合優化問題求解、偏微分方程求解等領域取得初步成效,證明其具備解決科學研究與計算問題的強大潛力。未來,AI for science將繼續驅動生命科學、醫藥研發、物理裝置控制、數學發現、材料發現與合成等領域創新發展,并將在跨界交叉領域進一步驅動產業創新和更廣泛的落地應用。同時,多模態大模型開啟了通用人工智能(AGI)發展道路,使AGI進展到“臨界點”。
未來10年,智能空間技術體系重構與再造面臨諸多挑戰。目前的智能感知可適應性差、認知機理不明、泛化能力弱等問題已經開始制約AI的更廣泛應用,亟待深入探索類人多模態感知、人機混合智能理論與方法,以及突破多源信息復雜場景和自主無人系統等決策、行為智能等。當前AI研究已經從深度學習時代走向“自監督+深度學習+強化學習”的大模型時代,以深度學習為基礎的人工智能理論已經遇到天花板,急需探索AI新的理論。Minyoung Huh等最近發表的“柏拉圖表征假說”,證明了神經網絡訓練,正趨向于在它的表征空間中收斂成一個共享的現實“世界統計模型”。Max Tegmark團隊發表的一項頗具顛覆性的研究,揭示了LLM中竟存在類似于人類大腦的腦葉分區結構,顯示出模型內部的幾何結構與人類大腦的功能分區有著驚人的相似性。這一發現表明,AI在某種程度上模仿了人類大腦的信息處理方式。這類研究不僅提供了理解LLM內部運作的新視角,也對AI的潛力有了更為深刻的認識,為未來AI的發展提供了新的理論支持。隨著研究的深入,未來或許能在大模型的基礎上,開發出更智能、更類人的AI。當前的多模態大模型面臨數據資源耗盡、能耗極大、成本極高和商業模式等問題。更重要的是,GPT-5研發受阻,文本域里規模定律(Scaling Law)可能已遇到天花板,而探索新型Scaling Law的預訓練多模態大模型、空間智能是不是就是通用人工智能(AGI)的發展技術路徑,還有待進一步的驗證。未來智能空間重構一個可能的途徑是在大模型、空間智能的基礎上,構建更多各種功能的智能體Agent,與大模型等進行深度融合與功能拓展,整合各種人工智能為一個集成的智能環境,如發展具身智能。但正如李國杰院士指出的,具身智能還有許多認知問題需要解決,這預示著未來通過具身智能發展AGI還面臨眾多挑戰。另外一個可能的途徑是Open AI發現的擴展測試時計算技術,即:在大模型推理階段,擴展思考和計算,進行反向多步推理,讓大模型能夠自主學習策略、拆解任務、識別并糾正錯誤。得益于思維鏈(CoT)推理的引入,Open AI o1模型是測試時計算的突破,證明了模型可以進行更深入的推理和解決更復雜的問題,為解決規模定律天花板問題和發展AGI提供了全新的思路。當然,還有其他可能的技術路徑,這些努力將加速AGI的到來。
發展對策
聚焦AI驅動的信息領域重大科技問題、突破關鍵理論與技術
我國信息科技領域既面臨短期破解局部“卡脖子”和建立自主技術體系與生態的長期需求,又要面臨后摩爾時代顛覆性技術創新突破、搶占科技制高點的歷史使命。因此,要持續加強信息科技領域的中長期戰略研究,聚焦新一代AI的理論、技術與新模型產品,聚焦發展AI之根基的各類高性能XPU算力芯片的設計與制造、高質量數據集和新型網絡的構建,以及高效能計算基礎設施建設等,將技術創新與工程實現和技術產品與市場生態建設等統一起來,組織科研院所與市場龍頭企業進行協同創新。一方面,聚焦“卡脖子”真問題,除芯片制造前道工藝EUV光刻機外,未來集成電路向3D芯片發展,前道工藝光刻機作用在減弱,高精度、高可靠與高性能的刻蝕機、薄膜機及電子束檢測設備等成為芯片制造關鍵設備,急需布局研制;同時自主架構高性能及開源RISC-V指令集的各種XPU芯片也需加強研發,并用相當長的時間打造我國信息技術與產業自主生態。另一方面,要抓住AI驅動全球信息技術領域正在進入重構與再造的創新機遇,系統研究計算技術、數據空間、算力空間、數據空間、網絡空間和智能空間的技術體系重構與再造面臨的挑戰性問題,協同市場龍頭企業,組織技術創新研發與工程實現隊伍,推進我國信息科技領域的整體創新。
布局信息領域重大科技基礎設施
沒有大的工程牽引、重大科技基礎設施支撐,信息科學不會有大的發展。信息科技發展歷史上,重大科技基礎設施為信息技術創新奠定了物質基礎,產生了一系列重大技術發明。例如,在互聯網領域,美國早期支持ARPANET的基礎設施,為人類創造了互聯網。圍繞未來網絡,美國組織了“從零開始”(“Clean Slate”)的革命性未來網絡研究,先后支持下一代互聯網研究基礎試驗設施(GENI)和從零開始設計新的互聯網架構(FIND)等項目。在云計算領域,美國也支持了全球信息網格(GIG)和云計算測試床(CloudLab)等項目。重大科技基礎設施的建設為美國等在信息科技領域領先,創造了極大的優勢。為抓住全球信息技術發展進入到緩慢期以及計算技術、算力空間、數據空間、網絡空間和智能空間等技術體系重構與再造的機遇期,我國應加快布局信息領域的重大基礎設施,搶占信息科技制高點。
一體化布局信息科技領域“裝置群”
在自然科學領域,往往圍繞一個或兩三個重大科學問題,構建一個大型的基礎設施,進行重大科學探索與發現的實驗研究。信息領域與之不同,信息領域的重大科技問題特征是:基礎原理、基礎共性技術和領域應用3類問題并存,許多重大科技問題分散在信息技術體系框架的各個部分;并且,信息科技的基本原理、共性技術等局部問題一旦突破,將能夠影響整個領域和其他領域的發展。我們不能指望通過一個集中化、實驗型的基礎設施來解決信息領域各個環節面臨的問題。因此,信息領域的重大科技基礎設施應該是一個“裝置群”,以應對各個子領域的科技問題。同時,信息領域的重大科技基礎設施應該是一個柔性可組合的離散、分布式“大裝置”,要進行一體化的布局。
(作者:洪學海,中國科學院計算技術研究所。《中國科學院院刊》供稿)
發佈留言